
Table of Links
Abstract and 1. Introduction
2. Method
3. Experiments on real data
4. Ablations on synthetic data
5. Why does it work? Some speculation
6. Related work
7. Conclusion, Impact statement, Environmental impact, Acknowledgements and References
A. Additional results on self-speculative decoding
B. Alternative architectures
C. Training speeds
D. Finetuning
E. Additional results on model scaling behavior
F. Details on CodeContests finetuning
G. Additional results on natural language benchmarks
H. Additional results on abstractive text summarization
I. Additional results on mathematical reasoning in natural language
J. Additional results on induction learning
K. Additional results on algorithmic reasoning
L. Additional intuitions on multi-token prediction
M. Training hyperparameters
B. Alternative architectures

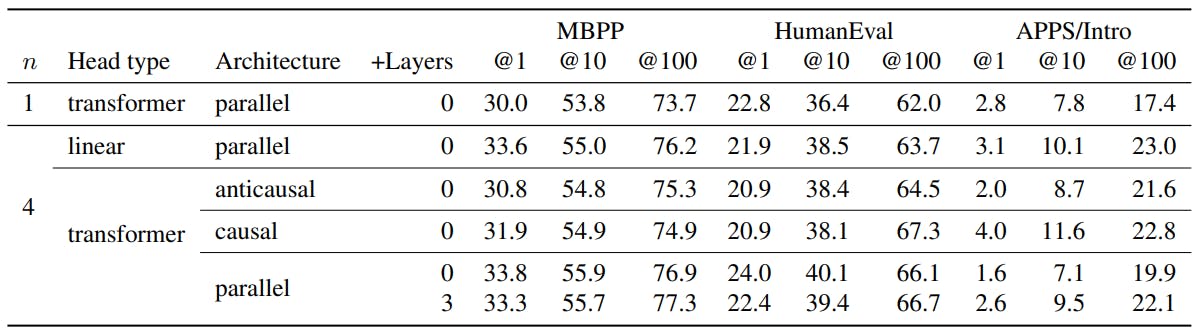
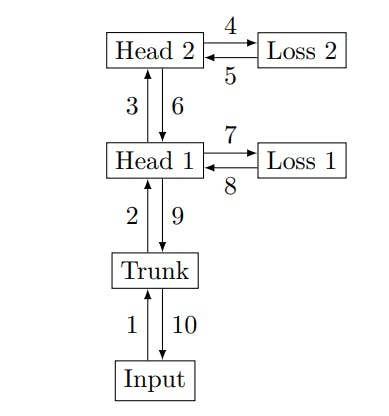
The architecture described in Section 2 is not the only sensible option, but proved technically viable and well-performing in our experiments. We describe and compare alternative architectures in this section.
Replicated unembeddings Replicating the unembedding matrix n times is a simple method for implementing multi-token prediction architectures. However, it requires matrices with shapes (d, nV ) in the notation of Section 2, which is prohibitive for large-scale trainings.
Linear heads Apart from using a single transformer layer for the heads Hi, other architectures are conceivable. We experimented with a single linear layer without any nonlinearity as heads, amounting to linear probing of the model’s residual representation z. Architectures with more than one layer per head are also possible, but we did not pursue this direction further.



Authors:
(1) Fabian Gloeckle, FAIR at Meta, CERMICS Ecole des Ponts ParisTech and Equal contribution;
(2) Badr Youbi Idrissi, FAIR at Meta, LISN Université Paris-Saclayand and Equal contribution;
(3) Baptiste Rozière, FAIR at Meta;
(4) David Lopez-Paz, FAIR at Meta and a last author;
(5) Gabriel Synnaeve, FAIR at Meta and a last author.
