Table of Links
Abstract and 1. Introduction
-
Related Work
2.1 Text to Vocal Generation
2.2 Text to Motion Generation
2.3 Audio to Motion Generation
-
RapVerse Dataset
3.1 Rap-Vocal Subset
3.2 Rap-Motion Subset
-
Method
4.1 Problem Formulation
4.2 Motion VQ-VAE Tokenizer
4.3 Vocal2unit Audio Tokenizer
4.4 General Auto-regressive Modeling
-
Experiments
5.1 Experimental Setup
5.2 Main Results Analysis and 5.3 Ablation Study
-
Conclusion and References
A. Appendix
A Appendix
The supplementary material is organized as follows: Sec. A.1 provides a website demo to show additional qualitative results; Sec. A.2 presents additional details of the network architectures; Sec. A.3 introduces evaluation metrics; Sec. A.4 presents additional ablation studies; Sec. A.5 shows additional qualitative results; Sec. A.6 discusses broader societal impacts of the work.
A.1 Website Demo
In order to provide more vivid and clear qualitative results, we make a supplemental website demo to demonstrate the generation quality of our proposed system. We encourage readers to view the results at https://vis-www.cs.umass.edu/RapVerse/.
A.2 Implementation Details
Motion Tokenizer. We train three separate Vector Quantized Variational Autoencoders (VQ-VAE) for face, body and hand, respectively. We adopt the same VQ-VAE architecture based on [14, 69, 23]. For loss functions optimizing the motion tokenizers, we use the L1 smooth reconstruction loss, the embedding loss, and the commitment loss. The commitment loss weight is set to 0.02. In line with [14, 23], strategies such as the exponential moving average and the codebook reset technique [49] are implemented to optimize codebook efficacy throughout the training process. We take 512 for the codebook size and set the dimension of each code to 512. We set the temporal down-sampling rate to 4. We train the VQ-VAEs with a batch size of 256 and a sequence window length of 72. We adopt Adam with β1 = 0.9, β2 = 0.99, and a learning rate of 0.0002 as the optimizer.
Vocal Tokenizer. For the semantic encoder, we adopt a BASE 12 transformer of HuBERT [20] pre-trained on the 969-hour LibriSpeech corpus [41]. Following [27, 45], we derive the feature activations from its sixth layer. This process allows the HuBERT model to transform input audio into a 768-dimensional vector space. Subsequently, we employ the k-means algorithm with 500 centroids to get quantized discrete content codes. For the F0 encoder, a VQ-VAE framework is utilized to discretize the F0 signal into quantized F0 tokens. We adopt the Exponential Moving Average updates during training the VQ-VAE following [6, 45]. We set the codebook size of the VQ-VAE to 20 entries. Moreover, as the original work directly normalizes the extracted F0 values for each singer respectively, we don’t explicitly use the singer’s statistics but adopt a windowed convolutional layer with both the audio input (sliced into the window size) and singer’s embedding as input. Finally, we adopt a similar architecture as [17] for the singer encoder.
General Auto-regressive Model. The auto-regressive model consists of a T5 Embedder and a Foundation Model. We use a T5-Large Encoder as our Embedder, with 24 layers and 16 heads. The Embedder is freezed during foundation model training. The foundation model is based on the Decoder-only transformer architecture, which has 12 layers and 8 heads. We use Adam optimizer with β1 = 0.9, β2 = 0.99, and a learning rate of 0.0002. We do not use dropout in our training. Our training batch size is 384 for 100 epochs
A.3 Evaluation Metrics
To evaluate the motion generation quality, we utilize the following metrics:
-
Frechet Inception Distance (FID): This metric measures the distribution discrepancy between the ground truth and generated motions of body and hand gestures. Specifically, we train an autoencoder based on [14] as the motion feature extractor.
-
Diversity (DIV): DIV evaluates the diversity of generated motions, where we calculate the variance from the extracted motion features.
-
Vertex MSE: Following [66], we compute the mean L2 error of lip vertices between generated face motions and ground truth.
-
Landmark Velocity Difference (LVD): Introduced by [68], LVD calculates the velocity difference of generated facial landmarks and ground truth.
-
Beat Constancy (BC) [29]: BC evaluates the synchrony of generated motions and singing vocals by calculating the similarity between the rhythm of gestures and audio beat. Specifically, we extract audio beats using librosa [36], and we compute the kinematic beats as the local minima of the velocity of joints. Then the alignment score is derived from the mean proximity of motion beats to the nearest audio beat.
For the evaluation of singing vocal generation quality, the Mean Opinion Score (MOS) is employed. It reflects the perceived naturalness of the synthesized vocal tones, with human evaluators rating each sample on a scale from 1 to 5, thereby offering a subjective measure of vocal synthesis fidelity.
A.4 Additional Ablation Studies
Ablation on Motion Tokenizer. We study different designs of our motion tokenizer by comparing the reconstruction results. Specifically, we explore VQ-VAEs with different codebook sizes, and study the effect of using a single VQ-VAE to model full-body motions instead of multiple VQ-VAEs for different body parts. As is demonstrated in Table. 4, we find that using separate VQ-VAEs for face, body and hands has lower reconstruction error. And we select a codebook size of 512 for our final model.
Ablation on Vocal Tokenizer. We also study different designs for our audio tokenizer by comparing the reconstruction results. Specifically, we explore different codebook sizes for the semantic encoder by changing the K-Means number. We also compare the effect with our singer embedding in F0 value postprocessing. We use the following metrics to measure the reconstruction quality of the vocal tokenizer:
![Table 4: Evaluation of our motion tokenizer. We follow [34] to evaluate the motion reconstruction errors of our motion VQVAE model Vm. MPJPE and PAMPJPE are measured in millimeters. ACCL indicates acceleration error.](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
![Table 4: Evaluation of our motion tokenizer. We follow [34] to evaluate the motion reconstruction errors of our motion VQVAE model Vm. MPJPE and PAMPJPE are measured in millimeters. ACCL indicates acceleration error.](https://hackernoon.imgix.net/images/hYnD3aGcZIgKnjRGl8QfkZDGyBF2-yi832yj.png?auto=format&fit=max&w=2048)
-
Character Error Rate (CER): We use Whisper [46] to transcribe the ground truth and synthesized audios, and then take the corresponding ground truth lyrics as the reference to calculate the CER of the synthesized audios.
-
Gross Pitch Error (GPE): The percentage of pitch estimates that have a deviation of more than 20% around the true pitch. Only frames considered pitched by both the ground truth and the synthesized audio are considered.
-
Voicing Decision Error (VDE) [38]: The portion of frames with voicing decision error, that is, the results using ground truth and synthesized audio to determine whether the frame is voiced are different.

![Table 5: Evaluation of our unit2wav model. We follow [45] to evaluate the speech resynthesis errors of our unit2wav model. WER, GPE, and VDE, expressed as percentages, indicate the character error rate, the grand pitch error and the voicing decision error.](https://hackernoon.imgix.net/images/hYnD3aGcZIgKnjRGl8QfkZDGyBF2-jc9325k.png?auto=format&fit=max&w=3840)
The analysis of the results indicates that even the original audio exhibits a high CER, which could be attributed to the rapid speech rate associated with rapping. In some instances, the lyrics may not be distinctly recognizable even by human listeners. Upon comparing different codebook sizes, it is observed that they achieve comparable GPE values. This similarity in GPE is expected since the same F0 model is employed across all codebook sizes. The CER, which serves as a direct measure of the semantic information preserved in the code, suggests that larger codebooks tend to retain more semantic information. However, the difference in CER between codebook sizes of K = 500 and K = 2000 is minimal. Given that K = 500 demonstrates better GPE and VDE, we select K = 500.
Additionally, we ablate a design without the singer embedding in the F0 preprocessing, instead normalizing the F0 values for each singer. It shows that this approach resulted in significantly inferior performance, particularly in pitch prediction, compared to the modified version that includes the singer embedding.
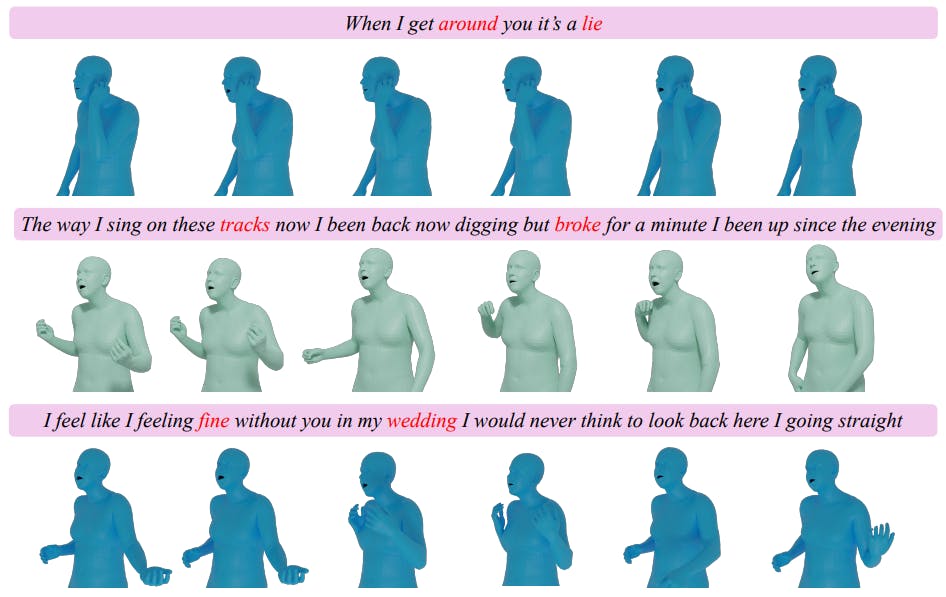
A.5 Additional Qualitative Results
We show additional qualitative results in Fig. 4. Our model adeptly generates comprehensive wholebody motions that embody the essence of the input lyrics. These include authentic gesture movements that resonate with the song’s rhythm and synchronized lip motions that articulate the lyrics.
A.6 Broader Impacts
This research contributes to advancements in generating synchronized vocals and human motion from textual lyrics, aiming to enhance virtual agents’ ability to provide immersive and interactive


experiences in digital media. The potential positive impact of this work lies in its ability to create more lifelike and engaging virtual performances, such as in virtual concerts and gaming, where characters can perform and react in ways that are deeply resonant with human expressions. This could significantly enhance user engagement in virtual reality settings, and provide innovative solutions in entertainment industries.
However, this capability carries inherent risks of misuse. The technology’s ability to generate realistic human-like actions and singing vocals from mere text raises concerns about its potential to create misleading or deceptive content. For example, this could be exploited to produce fake videos or deepfakes where individuals appear to sing and perform that never actually occurred, which could be used to spread misinformation or harm reputations. Recognizing these risks, it is crucial to advocate for ethical guidelines and robust frameworks to ensure the responsible use of such technologies.
Authors:
(1) Jiaben Chen, University of Massachusetts Amherst;
(2) Xin Yan, Wuhan University;
(3) Yihang Chen, Wuhan University;
(4) Siyuan Cen, University of Massachusetts Amherst;
(5) Qinwei Ma, Tsinghua University;
(6) Haoyu Zhen, Shanghai Jiao Tong University;
(7) Kaizhi Qian, MIT-IBM Watson AI Lab;
(8) Lie Lu, Dolby Laboratories;
(9) Chuang Gan, University of Massachusetts Amherst.

