Table of Links
Abstract and 1. Introduction
- Proposed Method: Quantized DyLoRA
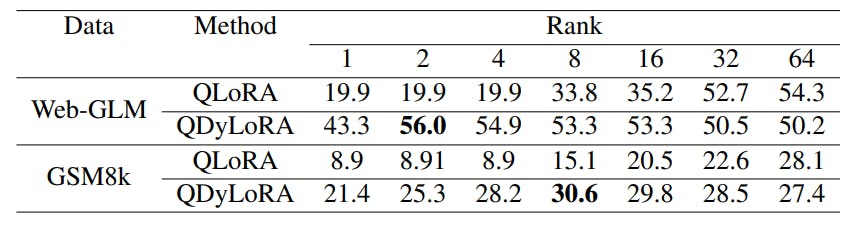
- Experiments and Evaluation
- On the semi-sorted behavior of QDyLoRA
- Conclusion, Limitations, and References
A. Supplementary Material
A.1. Hyperparameters
A.2. Generated Text Quality
Abstract
Finetuning large language models requires huge GPU memory, restricting the choice to acquire Larger models. While the quantized version of the Low-Rank Adaptation technique, named QLoRA, significantly alleviates this issue, finding the efficient LoRA rank is still challenging. Moreover, QLoRA is trained on a pre-defined rank and, therefore, cannot be reconfigured for its lower ranks without requiring further fine-tuning steps. This paper proposes QDyLoRA -Quantized Dynamic Low-Rank Adaptation-, as an efficient quantization approach for dynamic low-rank adaptation. Motivated by Dynamic LoRA, QDyLoRA is able to efficiently finetune LLMs on a set of pre-defined LoRA ranks. QDyLoRA enables fine-tuning Falcon-40b for ranks 1 to 64 on a single 32 GB V100-GPU through one round of fine-tuning. Experimental results show that QDyLoRA is competitive to QLoRA and outperforms when employing its optimal rank.
1 Introduction
The popularity of adopting Large Language Models (LLMs) across a diverse range of downstream tasks has rapidly increased over the past two years. Finetuning LLMs has become necessary to enhance their performance and introduce desired behaviors while preventing undesired outputs (Ding et al., 2023). However, as the size of these models increases, fine-tuning costs become more expensive. This has led to a large body of research that focuses on improving the efficiency of the fine-tuning stage (Liu et al., 2022; Mao et al., 2021; Hu et al., 2021; Edalati et al., 2022; Sung et al., 2022).
Low-rank adapter (LoRA) (Hu et al., 2021) is a well-known, parameter-efficient tuning (PEFT) method that reduces memory requirements during fine-tuning by freezing the base model and updating a small set of trainable parameters in form of low-rank matrix multiplication added to matrices in the base model. However, the memory demand during fine-tuning remains substantial due to the necessity of a backward pass through the frozen base model during stochastic gradient descent.
Recent research has thus focused on further reducing memory usage by designing new parameter-efficient modules that can be tuned without necessitating gradients from the base models (Sung et al., 2022). Alternatively, researchers have explored combining other efficiency strategies with parameter-efficient tuning methods (Kwon et al., 2022; Dettmers et al., 2023).
Among these approaches, QLoRA (Dettmers et al., 2023) stands out as a recent and highly efficient fine-tuning method that dramatically decreases memory usage. It enables fine-tuning of a 65-billion-parameter model on a single 48GB GPU while maintaining full 16-bit fine-tuning performance. QLoRA achieves this by employing 4- bit NormalFloat (NF4), Double Quantization, and Paged Optimizers as well as LoRA modules.
However, another significant challenge when utilizing LoRA modules is the need to tune their rank as a hyperparameter. Different tasks may require LoRA modules of varying ranks. In fact, it is evident from the experimental results in the LoRA paper that the performance of models varies a lot with different ranks, and there is no clear trend indicating the optimal rank. On the other hand, any hyperparameter tuning for finding the optimal rank contradicts the primary objective of efficient tuning and is not feasible for very large models. Moreover, when deploying a neural network on diverse devices with varying configurations, the use of higher ranks can become problematic for highly sensitive devices due to the increased parameter count. To address this, one typically has to choose between training multiple models tailored to different device configurations or determining the optimal rank for each device and task. However, this process is costly and time-consuming, even when using techniques like LoRA.
![Table 1: A comparison between QLoRA and QDyLoRA on the MMLU benchmark, reporting 5-shot test results for LLMs of varying sizes. QDyLoRA is evaluated on ranks [1,2,4,8,16,32,64] and the best rank is reported in brackets.](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
![Table 1: A comparison between QLoRA and QDyLoRA on the MMLU benchmark, reporting 5-shot test results for LLMs of varying sizes. QDyLoRA is evaluated on ranks [1,2,4,8,16,32,64] and the best rank is reported in brackets.](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-ig033k7.png?auto=format&fit=max&w=1920)
DyLoRA (Valipour et al., 2022), is a recent PEFT method that aims to address these challenges by employing dynamic Low-Rank Adapter (DyLoRA). Inspired by nested dropout, this method aims to order the representations of the bottleneck at low-rank adapter modules. Instead of training LoRA blocks with a fixed rank, DyLoRA extends training to encompass a spectrum of ranks in a sorted manner. The resulting low-rank PEFT modules not only provide increased flexibility during inference, allowing for the selection of different ranks depending on the context, but also demonstrate superior performance compared to LoRA, all without imposing any additional training time.
In this paper, we employ the DyLoRA PEFT method in conjunction with the quantization scheme utilized in the QLoRA work, resulting in QDyLoRA. QDyLoRA has all the aforementioned benefits of DyLoRA but with significant memory reduction both during training and at inference through 4-bit quantization. We utilize QDyLoRA for efficient fine-tuning of LLaMA-7b, LLaMA13b, and Falcon-40b models across ranks ranging from 1 to 64, all on a single 32GB V100 GPU. Once tuned, we determine the optimal rank by inferring the model on the test set. Our results reveal that the optimal rank can be quite low, yet it outperforms QLoRA.
1.1 Related Work
Low-rank PEFT methods These methods aim to fine-tune pre-trained LLMs for specific tasks while minimizing computational and memory resources. Low-rank adaptation techniques were inspired by (Aghajanyan et al., 2020), demonstrating that pre-trained language models possess a low intrinsic dimension. Since then, several works have explored the incorporation of trainable parameters in the form of low-rank up-projection/down-projection during fine-tuning. In (Houlsby et al., 2019), the Adapter module includes a down projection, a non-linear function, an up projection, and a residual connection. These modules are sequentially inserted after the feed-forward network (FFN) or attention blocks.
Additionally, (He et al., 2021) extends the Adapter concept by introducing trainable modules that run in parallel (PA) with the original pre-trained language model (PLM) module. As a result of this extension, PA has demonstrated improved performance compared to the original Adapter method. One notable approach among these techniques is LoRA (Hu et al., 2021), which introduces low-rank up-projection/down-projection into various matrices within a PLM. This method offers efficient inference by seamlessly integrating the adapter module into the original model’s weight matrices.
Quantization-aware PEFT methods AlphaTuning (Kwon et al., 2022), aims to combine parameter-efficient adaptation and model compression. Alpha-Tuning achieves this by employing post-training quantization, which involves converting the pre-trained language model’s full-precision parameters into binary parameters and separate scaling factors. During adaptation, the binary values remain fixed for all tasks, while the scaling factors are fine-tuned for the specific downstream task.
QLoRA (Dettmers et al., 2023) is a more recent quantization-aware PEFT that combines a low-rank adapter with 4-bit NormalFloat (NF4) quantization and Double Quantization (DQ) of the base model to optimize memory usage. NF4 ensures an optimal distribution of values in quantization bins, simplifying the process when input tensors have a fixed distribution. DQ further reduces memory overhead by quantizing quantization constants.
To manage memory during gradient checkpointing, QLoRA employs Paged Optimizers, utilizing NVIDIA’s unified memory feature for efficient GPU memory management. These techniques collectively enable high-fidelity 4-bit fine-tuning while effectively handling memory constraints.

Dynamic PEFT methods DyLoRA paper (Valipour et al., 2022) introduces a novel approach for training low-rank modules to work effectively across a range of ranks simultaneously, eliminating the need to train separate models for each rank.
Inspired by the concept of nested dropout, the authors propose a method for organizing the representations within low-rank adapter modules. This approach aims to create dynamic low-rank adapters that can adapt well to various ranks, rather than being fixed to a single rank with a set training budget. This is achieved by dynamically selecting ranks during training, allowing for greater flexibility without the need for extensive rank searching and multiple model training sessions.


This paper is