Table Of Links
Abstract
1 Introduction
2 Data Collection
3 RQ1: What types of software engineering inquiries do developers present to ChatGPT in the initial prompt?
4 RQ2: How do developers present their inquiries to ChatGPT in multi-turn conversations?
5 RQ3: What are the characteristics of the sharing behavior?
6 Discussions
7 Threats to Validity
8 Related Work
9 Conclusion and Future Work
References
\
Data Collection
In this section, we introduce the used dataset for our study (Section 2.1), followed by the used method utilized in preprocessing dataset (Section 2.2) and preparing datasets for research questions (Section 2.3). Figure 2 shows an overview of the data collection process and the used data for each of our RQs.
2.1 Data Source
Our research leverages the DevGPT dataset (Xiao et al., 2024) as the primary data source. DevGPT constitutes of an extensive archive of DeveloperChatGPT interactions, featuring 16,129 prompts and ChatGPT’s replies. Each shared conversation is coupled with the corresponding software development artifacts to enable the analysis of the context and implications of these developer interactions with ChatGPT. This collection was assembled by extracting shared ChatGPT links found in various GitHub components, such as source code, commits, pull requests, issues, discussions, and threads on Hacker News, over the period from July 27, 2023, to October 12, 2023. The DevGPT dataset is publicly available in a GitHub repository 4 , offering several snapshots. In this study, we focus on the most recent snapshot available as of October 12, 2023. 5
2.2 Data Preprocessing
As our analysis exclusively focuses on shared conversations occurring within GitHub issues and pull requests, we only consider the corresponding data provided by DevGPT, referred to as DevGPT-PRs and DevGPT-Issues. Based on our observations, we then perform the following two data preprocessing steps:
- The shared conversations contain sentences (prompts and replies) written in various human languages. To avoid potential misunderstanding from translating other languages different than English, we decided to only keep the conversations written in English. We utilized a Python library named lingua6 to identify conversations containing non-English content and removed those conversations. Specifically, we excluded 46 non-English conversations from DevGPT-PRs and 114 from DevGPT-Issues.
- The shared conversations contain duplicates, i.e., conversations with identical prompts and responses. We detected duplicate conversations and kept only one instance for analysis. Specifically, we removed 20 duplicated conversations from DevGPT-PRs and 83 duplicated conversations from DevGPT-Issues. After performing the above two data preprocessing steps, we ended up with 220 conversations from DevGPT-PRs, and 401 conversations from DevGPTIssues.
\
2.3 Preparing Data for RQs
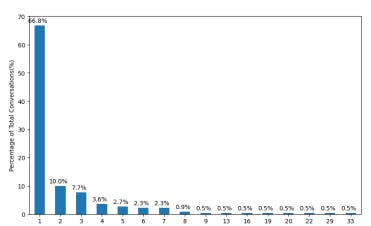
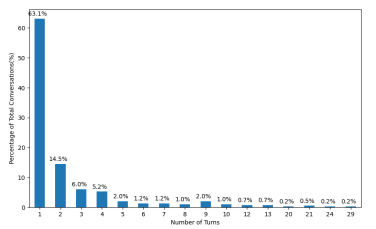
Figures 3 and 4 show the distribution of conversational turns within the preprocessed datasets. As shown in these figures, a large majority of shared conversations in both DevGPT-PRs (66.8%) and DevGPT-Issues (63.1%) are single-turn interactions. Meanwhile, conversations extending beyond 8 turns – comprising 8 prompts and their 8 corresponding replies – are notably infrequent, accounting for only 4% in DevGPT-PRs and 6% in DevGPT-Issues.
\
Given this distribution, we choose to implement a cutoff at 8 turns for RQ1-3 involving both datasets. This approach allows us to concentrate our investigation on the most prevalent patterns of interaction, thereby ensuring that our analysis remains closely aligned with the conversational dynamics that characterize the vast majority of the dataset. Following this cutoff, the finalized datasets encompass a total of 212 conversations for DevGPT-PRs and 375 for DevGPT-Issues As shown in Figure 2, in RQ1, we analyzed the contents of 580 initial prompts 7 .
\
In RQ2, we analyzed the content in the 645 prompts within all 189 multi-turn conversations. For RQ3, we extend our manual analysis to pull requests and issues that contain shared conversations. Specifically, we randomly sampled a statistically significant set containing 90 GitHub pull request comments and 160 GitHub issue comments containing shared conversations from DevGPT-PRs and DevGPT-Issues. The sampling is based on the results of RQ2. The detailed process is presented in the approach of RQ3 in Section 5.
:::info
Authors
- Huizi Hao
- Kazi Amit Hasan
- Hong Qin
- Marcos Macedo
- Yuan Tian
- Steven H. H. Ding
- Ahmed E. Hassan
:::
:::info
This paper is available on arxiv under CC BY-NC-SA 4.0 license.
:::
\