Table of Links
-
Introduction
-
Related Work
2.1 Semantic Typographic Logo Design
2.2 Generative Model for Computational Design
2.3 Graphic Design Authoring Tool
-
Formative Study
3.1 General Workflow and Challenges
3.2 Concerns in Generative Model Involvement
3.3 Design Space of Semantic Typography Work
-
Design Consideration
-
Typedance and 5.1 Ideation
5.2 Selection
5.3 Generation
5.4 Evaluation
5.5 Iteration
-
Interface Walkthrough and 6.1 Pre-generation stage
6.2 Generation stage
6.3 Post-generation stage
-
Evaluation and 7.1 Baseline Comparison
7.2 User Study
7.3 Results Analysis
7.4 Limitation
-
Discussion
8.1 Personalized Design: Intent-aware Collaboration with AI
8.2 Incorporating Design Knowledge into Creativity Support Tools
8.3 Mix-User Oriented Design Workflow
-
Conclusion and References
5 TYPEDANCE
Based on the identified design rationales and the highlighted opportunity to address the challenges and concerns in the design workflow, we have developed TypeDance, an authoring system that facilitates personalized generation for semantic typographic logos. TypeDance comprises five essential components, which closely correspond to the pregeneration, generation, and post-generation stages. In the pre-generation stage, the ideation component communicates with the user to gather comprehensible imageries (D1). The selection component allows the user to choose specific design materials, including typeface at various granularities and imagery with particular visual representations (D2). The generation component blends these design materials, utilizing a series of combinable design priors (D3). After the generation, the evaluation component enables the user to assess the current result’s position in the type-imagery spectrum (D4). The iteration component empowers user to refine their design by adjusting the type-imagery spectrum and editing each individual element (D5).
5.1 Ideation
Thanks to the impressive language understanding and reasoning capabilities of large language models, we can now collaborate with a knowledgeable brain through text. TypeDance takes advantage of Instruct GPT-3 (davinci-002) [36] with Chain-of-Thought prompting [53] to generate relevant imagery based on given texts. To enhance user understanding, the prompting strategy includes the requirement to accompany the imagery with explanations in terms of visual design. This ensures that the answers provided are more interpretable and informative. For example, when the user provides the keyword “Hawaii,” TypeDance generates concrete imagery such as “Aloha Shirt,” “Hula Dancer,” and “Palm tree.” Along with these imagery words, TypeDance also provides explanations like “Symbolizes the vibrant culture and traditional dance form of Hawaii” for the “Hula Dancer”. By making this small change, TypeDance provides interpretable explanations and offers users additional background knowledge to enhance their understanding.
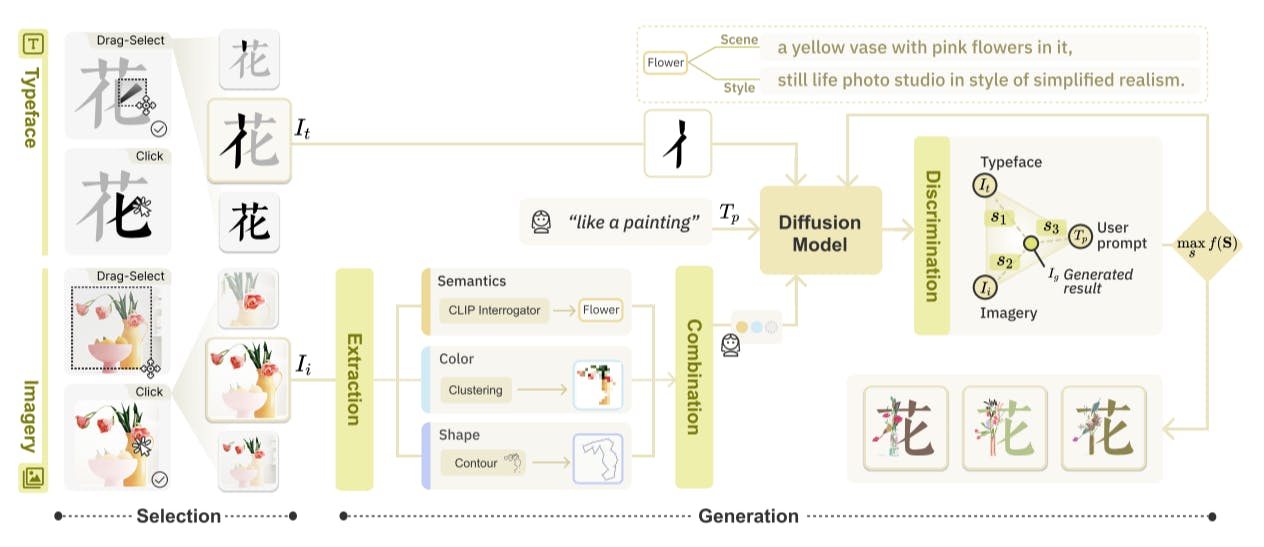
5.2 Selection
The selection aims to prepare design materials blended in the following generation. It encompasses two fundamental components: selecting typeface 𝐼𝑡 at various granularities and imagery 𝐼𝑖 with particular visual representations. We achieve the fine-grained high-fidelity segmentation based on Segment Anything Model [25], which offers user-friendly


visual prompts as input, including box and point. As illustrated in Fig. 4, the different characteristics inherent to typefaces and imagery give rise to varying interactions that aim to align with the design rationales.
Typeface Selection. Given the text, TypeDance allows creators to select typefaces 𝐼𝑡 at different granularity, as identified in our formative study, to achieve a more fine-grained and flexible approach to complex design practices. Instead of being limited to using complete strokes, TypeDance enables creators to select partial regions of a single stroke. To achieve this, As Fig. 4 shows, we implemented the drag-select interaction for creators to encompass specific parts of the typeface they need within a designated box. Compared to the click interaction, the drag-select offers a more explicit way to reveal user intention, which is free from rule-based segmentation that is restricted by a set of predetermined strokes, thus supporting more fine-grained selection. Moreover, TypeDance offers a combination selection by which creators can select strokes located far apart, as in the case shown in Fig. 4.
Imagery Selection. Regarding imagery selection, we employ semantic segmentation to extract the visual representation creators require from a cluttered background. However, unlike typeface selection, the nature of imagery selection is more conducive to clicking rather than drag-selection. As depicted in Fig. 4, drag-selection can inadvertently encompass other objects the creator may not need while selecting their desired object. To address this issue, we have implemented a solution where creators can click on individual objects separately, mitigating the problem of unintentional object coverage. Similarly to typeface selection, TypeDance also supports combination selection, allowing creators to choose multiple objects within the image.
Authors:
(1) SHISHI XIAO, The Hong Kong University of Science and Technology (Guangzhou), China;
(2) LIANGWEI WANG, The Hong Kong University of Science and Technology (Guangzhou), China;
(3) XIAOJUAN MA, The Hong Kong University of Science and Technology, China;
(4) WEI ZENG, The Hong Kong University of Science and Technology (Guangzhou), China.
This paper is

