Authors:
(1) Anthi Papadopoulou, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway and Corresponding author ([email protected]);
(2) Pierre Lison, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(3) Mark Anderson, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(4) Lilja Øvrelid, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway;
(5) Ildiko Pilan, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway.
Table of Links
Abstract and 1 Introduction
2 Background
2.1 Definitions
2.2 NLP Approaches
2.3 Privacy-Preserving Data Publishing
2.4 Differential Privacy
3 Datasets and 3.1 Text Anonymization Benchmark (TAB)
3.2 Wikipedia Biographies
4 Privacy-oriented Entity Recognizer
4.1 Wikidata Properties
4.2 Silver Corpus and Model Fine-tuning
4.3 Evaluation
4.4 Label Disagreement
4.5 MISC Semantic Type
5 Privacy Risk Indicators
5.1 LLM Probabilities
5.2 Span Classification
5.3 Perturbations
5.4 Sequence Labelling and 5.5 Web Search
6 Analysis of Privacy Risk Indicators and 6.1 Evaluation Metrics
6.2 Experimental Results and 6.3 Discussion
6.4 Combination of Risk Indicators
7 Conclusions and Future Work
Declarations
References
Appendices
A. Human properties from Wikidata
B. Training parameters of entity recognizer
C. Label Agreement
D. LLM probabilities: base models
E. Training size and performance
F. Perturbation thresholds
3 Datasets
There only exists a few generic (non-medical) datasets that are devoted to the evaluation of text sanitization approaches. We present below the two datasets used for training, evaluation and error analysis throughout this paper.
3.1 Text Anonymization Benchmark (TAB)
The TAB corpus (Pil´an et al., 2022) is a collection of 1268 European Court of Human Rights (ECHR) court cases, manually annotated to protect the identity of the individual mentioned in the text. These court cases are documents rich in PII that are also freely available to use. The documents are in English and each court case is annotated, among others, with an individual to be protected as well as with detected PII spans containing the following information:

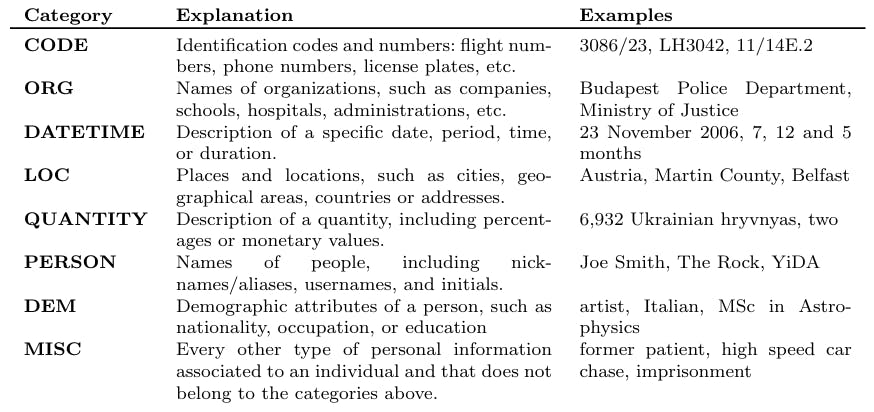
• The span’s semantic type, according to the 8 categories established in Pil´an et al. (2022), described in Table 1.
• Whether that span needs to be masked in order to protect the privacy of the specified individual, with three possible values: DIRECT, QUASI, or NO MASK.
• Whether the span is a confidential attribute of the individual, such as religious or philosophical beliefs, political opinions, sexual orientation or sex life, racial or ethnic origin, and health, genetic and biometric data.
• Co-reference links between relevant spans that refer to the same entity.
Example 1 illustrates a short excerpt where spans underlined in black were marked by the annotators, and those underlined in dark green were categorized by the annotator as denoting a direct or quasi-identifier to mask.
Example 1. The case originated in an application (no. 44521/04) against the Republic of Poland lodged with the Court under Article 34 of the Convention for the Protection of Human Rights and Fundamental Freedoms (“the Convention”) by a Polish national, Mr Leszek Ko lodzi´nski (“the applicant”), on 19 August 2004.
The documents are, on average, 1,442 tokens long. The majority of the tokens are labeled as QUASI identifiers (63%), with fewer tokens being masked as DIRECT identifiers (4.4%) and the rest of the annotated text spans being left unmasked by the annotators. The majority of the identifiers belonged to the DATETIME, ORG, and PERSON categories which is in line with the domain of the texts.
Some of the court cases (274) were also multi-annotated to allow for evaluation against different solutions since the task is subjective in nature. The inter-annotator agreement on the identifier type (DIRECT, QUASI, NO-MASK), calculated both on the span (k = 0.46) and character level (k = 0.79), shows moderate agreement which is to be expected from a task where multiple correct solutions can exist. We follow the training, development, and test split the authors release with 1,014, 127 and 127 documents respectively.
3.2 Wikipedia Biographies
Papadopoulou et al. (2022) released a collection of 553 Wikipedia biographies manually annotated for text anonymization. The annotation task was similar to that of the TAB corpus, except for the absence of annotation for confidential attributes, which was not relevant for this dataset.
Example 2 shows a manually annotated text, both for detected PII spans (underlined in black), and also for masking decision (underlined in dark green).
Example 2. David Sherwood is a British tennis coach and retired tennis player. In his only live Davis Cup match, Sherwood played doubles with Andy Murray beating the Israeli World No 4 doubles team of Jonathan Erlich and Andy Ram.
The documents in this dataset are much shorter than those in the TAB corpus. A large majority of the PII spans were marked by the annotators as QUASI identifiers to be masked (56%) or DIRECT identifiers (14%), while 30% of the spans were left as is in the text without needing to be masked, as they were deemed less specific by the annotators and thus, less risky. Most of the identifiers in this dataset belong to the DATETIME, ORG, and PERSON semantic types.
Of the 553 documents, 22 were also doubly-annotated to account for multiple correct solutions for this task. Cohen’s k calculated both in the span (k = 0.44) and the character level (k = 0.81) on the masking decision showed moderate agreement, highlighting the subjective nature of the task. We follow the split proposed in Olstad et al. (2023), which includes all the double-annotated documents in the test set (100 documents), while 453 documents are available for training purposes.