At 21st.dev, we’re building what we call “the NPM for Design Engineers” — a marketplace and hub for reusable UI building blocks. One of our core challenges has been creating an effective search system that transcends lexical matching limitations to understand the semantic topology of UI components.
In this article, we’ll dissect our implementation of a high-dimensional vector space model for React component retrieval, leveraging OpenAI transformer-based embedding models, generative augmentation through Hypothetical Document Embeddings (HyDE), and diversification via Maximal Marginal Relevance (MMR) optimization.
TL;DR: We developed a retrieval system for UI components that combines transformer-based embeddings with generative pre-processing. This approach enables latent semantic querying with natural language expressions rather than strict term matching, resulting in significant improvements to precision@k metrics and mean reciprocal rank scores in our evaluation framework.
The Problem: Why Traditional Text Search Fails for UI Components
Traditional information retrieval systems for UI components suffer from fundamental limitations that prevent developers from efficiently finding the components they need:
Key Limitations
Intent vs. Implementation Gap
-
Developers search for what they functionally need (“dropdown with nested options”) rather than how it’s implemented (“ul with recursive child components and event handlers”).
-
Query intents frequently operate at a higher abstraction level than implementation details.
⠀Vocabulary Mismatch Problem
-
Different developer communities use varied nomenclature for identical patterns (“modal” vs. “dialog” vs. “overlay”).
-
These cross-domain terminological gaps create significant retrieval challenges.
⠀Lexical-Semantic Dissonance
-
Term-based retrieval models (BM25, TF-IDF) fail to capture functional equivalence between differently named but semantically identical UI patterns.
-
Components with similar functionality but different naming conventions become virtually undiscoverable.
⠀Representational Sparsity
- A component’s purpose can’t be fully captured by the words in its code or metadata.
- Conventional sparse vector representations struggle to express the rich functional similarity required for effective component matching.
The Unique Challenge of Component Retrieval
A developer searching for “hierarchical selection with asynchronous loading” expects to find semantically relevant components despite the potential absence of lexical overlap. Similarly, someone looking for “a date picker with range selection” needs to find appropriate components even if none contain those exact terms.
Traditional text search approaches break down in this domain precisely because the meaning and functionality of UI components transcend their textual representation.
Vector Embeddings + AI Understanding
Our approach combines:
1. Dual-vector embeddings (usage and code)
2. AI-generated component descriptions
3. Hypothetical Document Enhancement (HyDE)
4. Maximal Marginal Relevance (MMR) for result diversity
Technical Architecture Overview
Our search system consists of three main parts:
1. Embedding Generation Pipeline: Creates vector representations of components
2. Search & Retrieval System: Processes queries and finds matching components
3. Data Storage Model: Stores and indexes embeddings in a vector database

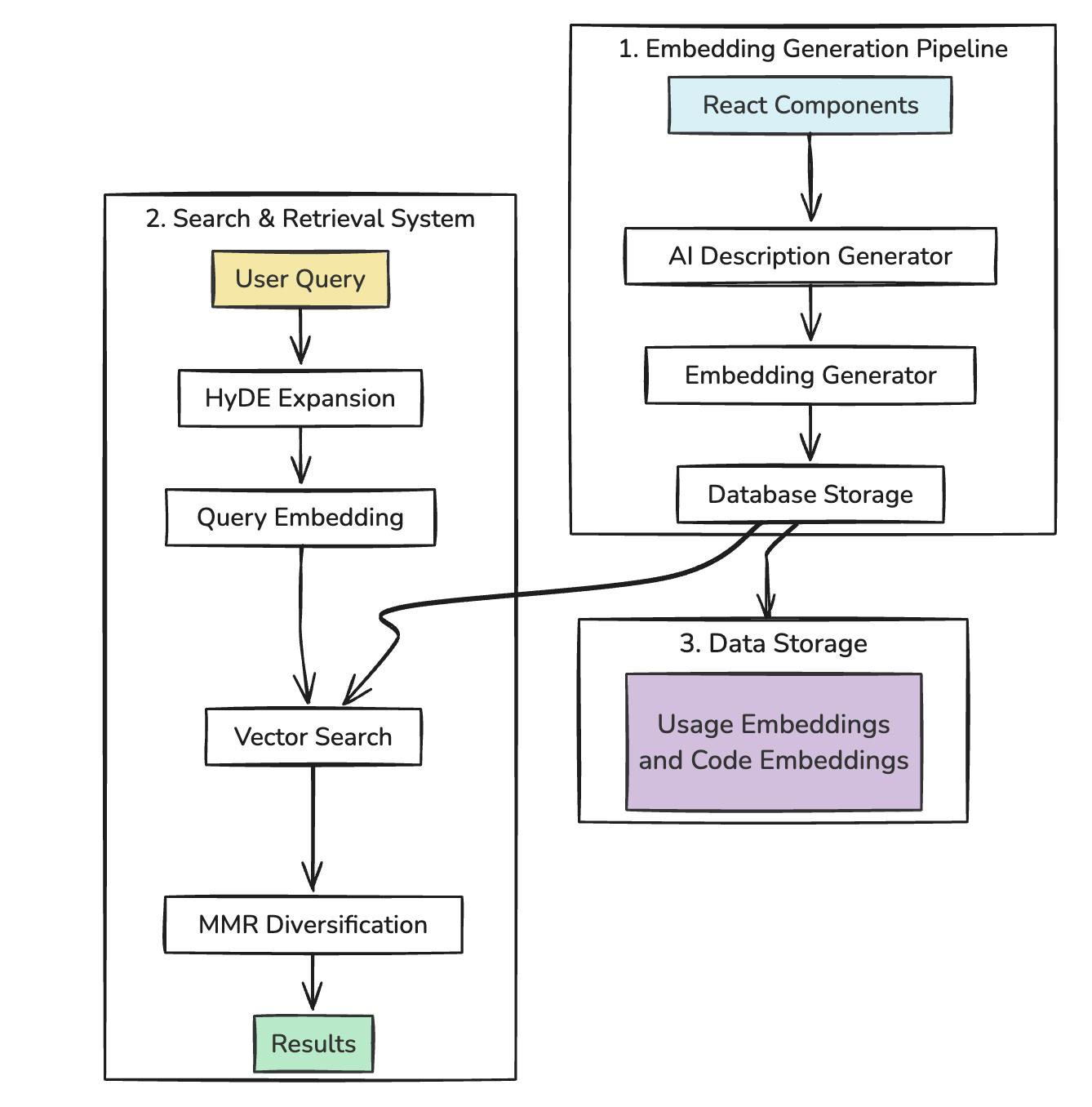
This architecture allows us to efficiently generate, store, and query vector embeddings of UI components, creating a semantic search experience that understands developer intent rather than just matching keywords.
Generating Meaningful Embeddings
The heart of our system is the embedding generation process. For each UI component and demo in our library, we generate two types of embeddings:
- Usage Embeddings: Represent how a component is used and its functionality
- Code Embeddings: Represent the actual code structure and implementation
The Embedding Generation Process
The process of generating meaningful embeddings involves several steps:

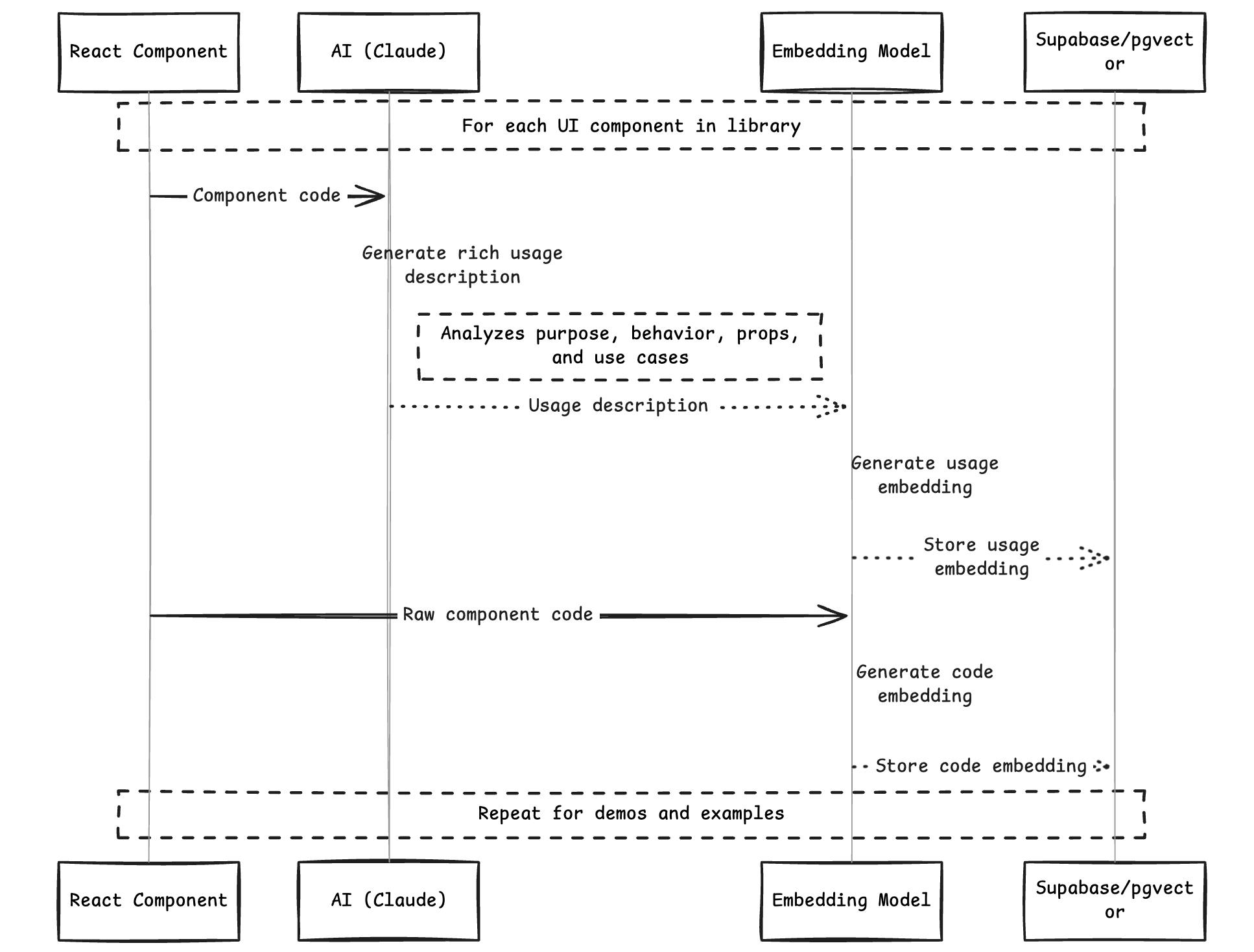
This sequence illustrates how we transform raw component code into searchable vector embeddings, with AI-generated descriptions providing semantic context.
Here’s how we implement this in code:
// From supabase/functions/generate-embeddings/index.ts
interface Component {
id: number;
name: string;
code: string;
}
interface EmbeddingMetadata {
component_id: number;
component_name: string;
code_preview: string;
last_updated: string;
}
async function generateComponentEmbeddings(componentId: number): Promise {
try {
// Fetch component data
const { data: component, error: componentError } = await supabase
.from("components")
.select("id, name, code")
.eq("id", componentId)
.single();
if (componentError || !component) {
throw new Error(`Failed to fetch component: ${componentError?.message}`);
}
// Get component code (resolving URL if needed)
const componentCode = await fetchCodeFromUrl(component.code);
// 1. Generate usage-oriented description based on the component code
const usageDescription = await generateUsageDescription({
componentName: component.name,
componentCode,
demoCode: "", // No demos text for this case
});
// 2. Generate embedding for usage description
const usageEmbedding = await generateEmbedding(usageDescription);
// Prepare metadata for storage
const metadata: EmbeddingMetadata = {
component_id: component.id,
component_name: component.name,
code_preview: componentCode.substring(0, 100) + "...",
last_updated: new Date().toISOString(),
};
// Store usage embedding
await supabase.from("usage_embeddings").upsert({
item_id: componentId,
item_type: "component",
embedding: usageEmbedding,
usage_description: usageDescription,
metadata,
});
// 3. Generate embedding for code
const codeEmbedding = await generateEmbedding(componentCode);
// Store code embedding
await supabase.from("code_embeddings").upsert({
item_id: componentId,
item_type: "component",
embedding: codeEmbedding,
metadata,
});
console.log(`Successfully generated embeddings for component ${componentId}`);
} catch (error) {
console.error(`Error generating embeddings for component ${componentId}:`, error);
throw error;
}
}
The key innovation here is using AI (Anthropic’s Claude) to generate rich descriptions of what each component does, based on analyzing its code:
// Example of the AI prompt used to generate usage descriptions
const USAGE_PROMPT = `
You are an expert UI developer tasked with describing a React component's functionality.
Analyze the component code and generate a detailed description focusing on:
1. The component's primary purpose and functionality
2. UI appearance and behavior
3. Interactive elements and states
4. Props and customization options
5. Common use cases
Your description should help other developers understand when and how to use this component.
`;
Why Generate AI Descriptions?
Raw code often lacks explicit information about a component’s purpose or typical use cases. By having Claude analyze the code and generate natural language descriptions, we create rich semantic context that can be embedded and searched.
These descriptions are then embedded using OpenAI’s text-embedding-3-small model, creating 1536-dimensional vectors that capture the semantic meaning of each component.
The Search Engine: HyDE + Vector Similarity + MMR
Our search system goes beyond simple vector similarity lookups, implementing several advanced techniques.
Here’s how a query flows through our search system:

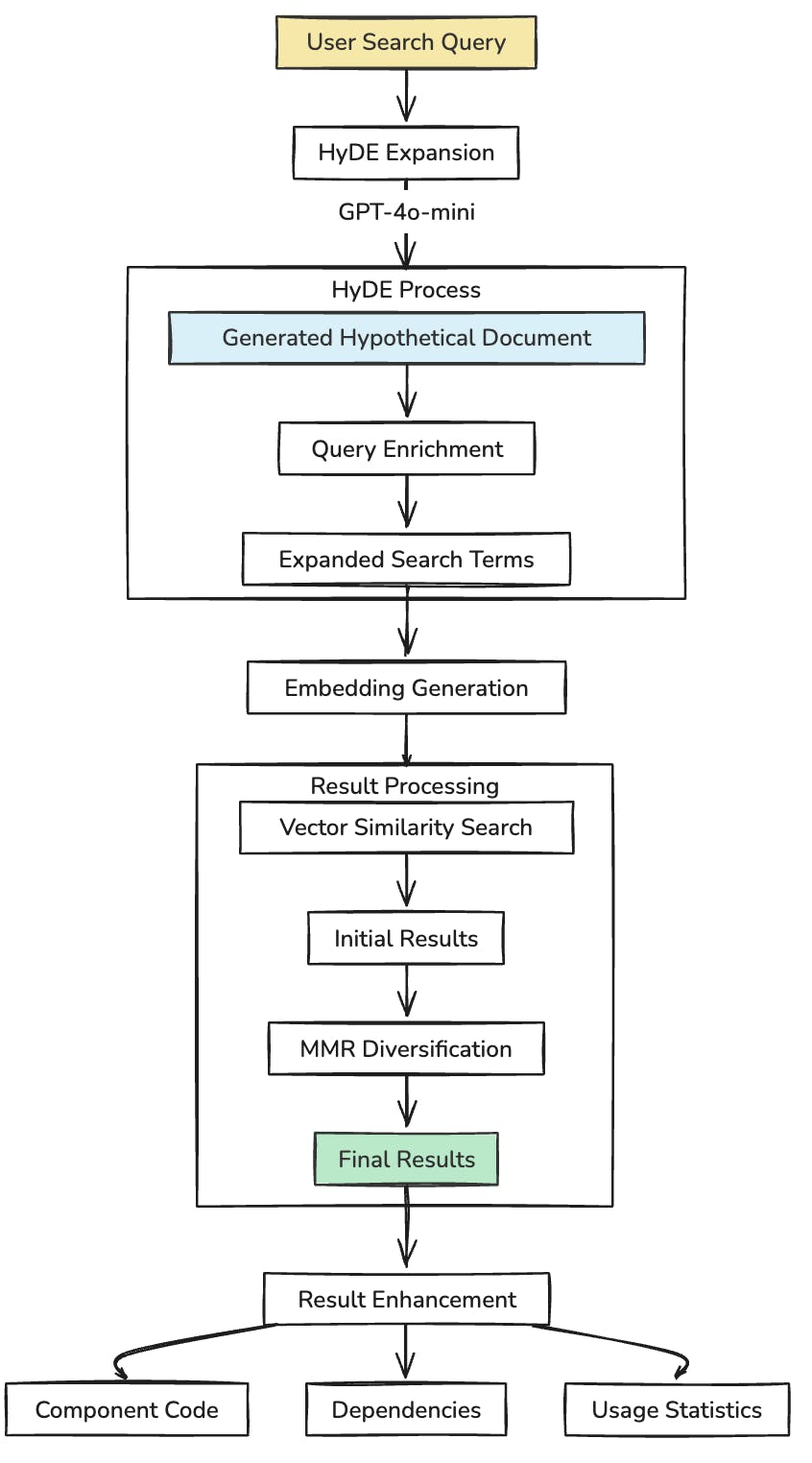
This approach allows us to transform vague user queries into rich, contextual searches that can find semantically relevant components even when there’s no direct keyword match.
1. HyDE (Hypothetical Document Embeddings)
A key challenge in semantic search is that user queries are often short and ambiguous. HyDE addresses this by using an LLM to expand the query into a hypothetical document that would satisfy it.
Here’s our implementation:
// From supabase/functions/search-embeddings/index.ts
interface HyDEDocument {
searchQueries: string;
fullDocument: string;
}
// HyDE (Hypothetical Document Embeddings) generation
async function generateHypotheticalDocument(
query: string,
userMessage: string,
): Promise {
try {
// Ensure query exists with fallback to empty string
const safeQuery = query?.trim() || "";
const safeUserMessage = userMessage?.trim() || "";
// Combine query and user message for better context
const combinedInput = `Search Query: ${safeQuery}\nUser Request: ${safeUserMessage}`;
// Generate search queries using GPT-4o-mini
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content: HYDE_PROMPT,
},
{
role: "user",
content: combinedInput,
},
],
temperature: 0.7,
max_tokens: 1000,
});
const hydeDocument = response.choices[0]?.message?.content || "";
// Extract and clean up the generated queries
const searchQueries = hydeDocument
.split("\n")
.map((line) => line.trim())
.filter((line) => line.startsWith("-"))
.join("\n");
// If no queries were generated, fallback to default
if (!searchQueries) {
return createFallbackDocument(safeQuery, safeUserMessage);
}
return {
searchQueries,
fullDocument: `${safeQuery}\n${safeUserMessage}\n${searchQueries}`,
};
} catch (error) {
console.error("Error generating hypothetical document:", error);
return createFallbackDocument(query, userMessage);
}
}
// Helper function for fallback document creation
function createFallbackDocument(query: string, userMessage: string): HyDEDocument {
const safeQuery = query?.trim() || "";
const safeUserMessage = userMessage?.trim() || "";
return {
searchQueries: `- ${safeQuery}${safeUserMessage ? `\n- ${safeUserMessage}` : ""}`,
fullDocument: `${safeQuery}\n${safeUserMessage}`,
};
}
For example, if a user searches for “dropdown with icons”, HyDE might generate:
- React dropdown component with icon support
- Customizable select menu with icon prefixes for options
- Interactive dropdown that displays icons alongside option text
- UI component for selecting from options with visual icon indicators
We then embed this expanded description instead of the original query, resulting in much better semantic matches.
2. Vector Similarity Search
With our query embedding in hand, we search for similar components using a vector similarity search:
// From supabase/functions/search-embeddings/index.ts
interface SearchResult {
id: number;
name: string;
item_type: 'component' | 'demo';
similarity: number;
usage_description?: string;
metadata: Record;
}
interface SearchOptions {
match_threshold?: number;
match_count?: number;
includeMetadata?: boolean;
}
// Main search function for components and demos
async function searchComponents(
supabase: SupabaseClient,
search: string,
options: SearchOptions = {},
userMessage: string = "",
): Promise {
// Default search parameters
const {
match_threshold = 0.33,
match_count = 15,
includeMetadata = true
} = options;
// Generate hypothetical document for better search context
const hydeDocuments = await generateHypotheticalDocument(search, userMessage);
// Get embedding for generated queries
const hydeEmbedding = await generateEmbedding(hydeDocuments.searchQueries);
// Search with embeddings using the database RPC function
const { data: results, error } = await supabase.rpc(
"match_embeddings_with_details",
{
query_embedding: hydeEmbedding,
match_threshold,
match_count,
include_metadata: includeMetadata,
},
);
if (error) {
console.error("Error searching with embeddings:", error);
throw new Error(`Search failed: ${error.message}`);
}
// Apply MMR if we have sufficient results
if (results && results.length > 1) {
// Transform results to include embeddings for MMR
const resultsWithEmbeddings = results.map(result => ({
id: result.id,
embedding: result.embedding as number[],
score: result.similarity
}));
// Get diversified results using MMR
const diversifiedIds = maximalMarginalRelevance(
hydeEmbedding,
resultsWithEmbeddings
);
// Reorder results based on MMR
return diversifiedIds.map(id =>
results.find(result => result.id === id)
).filter(Boolean) as SearchResult[];
}
return results || [];
}
We use Supabase’s pgvector extension to handle the vector similarity search efficiently, with an RPC function that performs the search directly in the database.
3. MMR (Maximal Marginal Relevance)
To ensure diverse results, we implement MMR, which balances relevance against redundancy:
// From supabase/functions/search-embeddings/index.ts
interface EmbeddingCandidate {
id: number;
embedding: number[];
score: number;
}
/**
* Implements Maximal Marginal Relevance algorithm for diversifying search results
*
* MMR balances between relevance to the query and diversity among selected items:
*
* score = λ * sim(query, candidate) - (1-λ) * max(sim(candidate, selected_items))
*
* @param queryEmbedding - The embedding vector of the search query
* @param candidateEmbeddings - List of candidate items with their embeddings and relevance scores
* @param lambda - Balance parameter between relevance (1.0) and diversity (0.0)
* @param k - Number of results to return
* @returns Array of selected item IDs in order of selection
*/
function maximalMarginalRelevance(
queryEmbedding: number[],
candidateEmbeddings: EmbeddingCandidate[],
lambda: number = 0.5,
k: number = DEFAULT_SEARCH_LIMIT,
): number[] {
// If we have fewer candidates than k, return all candidates
if (candidateEmbeddings.length <= k) {
return candidateEmbeddings.map((item) => item.id);
}
// Sort candidates by initial relevance score
const sortedCandidates = [...candidateEmbeddings].sort((a, b) => b.score - a.score);
// Initialize with most relevant item
const selectedIds: number[] = [sortedCandidates[0].id];
const selectedEmbeddings: number[][] = [sortedCandidates[0].embedding];
// Remove the first item from candidates
const remainingCandidates = sortedCandidates.slice(1);
// Select k-1 more items
while (selectedIds.length < k && remainingCandidates.length > 0) {
let nextBestId = -1;
let nextBestScore = -Infinity;
let nextBestIndex = -1;
// Evaluate each remaining candidate
for (let i = 0; i < remainingCandidates.length; i++) {
const candidate = remainingCandidates[i];
// Relevance term (similarity to query)
const relevance = candidate.score;
// Diversity term (negative max similarity to any selected item)
let maxSimilarity = -Infinity;
for (const selectedEmbedding of selectedEmbeddings) {
const similarity = computeSimilarity(
candidate.embedding,
selectedEmbedding,
);
maxSimilarity = Math.max(maxSimilarity, similarity);
}
// MMR score combines relevance and diversity
// Higher lambda prioritizes relevance, lower lambda prioritizes diversity
const mmrScore = lambda * relevance - (1 - lambda) * maxSimilarity;
if (mmrScore > nextBestScore) {
nextBestScore = mmrScore;
nextBestId = candidate.id;
nextBestIndex = i;
}
}
// Add the next best item
if (nextBestIndex !== -1) {
selectedIds.push(nextBestId);
selectedEmbeddings.push(remainingCandidates[nextBestIndex].embedding);
remainingCandidates.splice(nextBestIndex, 1);
} else {
break; // No more suitable candidates
}
}
return selectedIds;
}
This algorithm works by:
- Selecting the most relevant result first
- For each subsequent selection, calculating a score that balances relevance to the query against similarity to already selected items
- Selecting the item with the highest balanced score
With MMR, users see a variety of components that might meet their needs, rather than many variations of the same component type.
API Layer: Tying Everything Together
Our Next.js API route serves as the integration point for the entire system:
// From apps/web/app/api/magic-search/route.ts
interface SearchRequest {
query: string;
context?: string;
api_key: string;
match_threshold?: number;
result_limit?: number;
}
interface SearchResultItem {
id: number;
name: string;
item_type: 'component' | 'demo';
similarity: number;
usage_description?: string;
metadata: Record;
}
interface EnhancedResultItem {
id: number;
name: string;
code: string;
demos: Array<{
id: number;
name: string;
code: string;
}>;
similarity_score: number;
dependencies: string[];
usage_description: string;
total_usages: number;
}
/**
* API endpoint for searching components using vector embeddings
*/
export async function POST(req: Request): Promise {
try {
// Parse and validate request
const body = await req.json() as SearchRequest;
const {
query,
context = "",
api_key,
match_threshold = 0.33,
result_limit = 8
} = body;
if (!query?.trim()) {
return new Response(
JSON.stringify({ error: "Query is required" }),
{ status: 400, headers: { "Content-Type": "application/json" } }
);
}
// Validate API key
const { data: apiKeyValid, error: keyError } = await supabase.rpc("check_api_key", {
key_to_check: api_key,
});
if (keyError || !apiKeyValid) {
return new Response(
JSON.stringify({ error: "Invalid API key" }),
{ status: 401, headers: { "Content-Type": "application/json" } }
);
}
// Call the search-embeddings function
const { data: searchResults, error: searchError } = await supabase.functions.invoke(
"search-embeddings",
{
body: JSON.stringify({
search: query,
user_message: context,
match_threshold,
result_limit,
}),
}
);
if (searchError || !searchResults) {
console.error("Search failed:", searchError);
return new Response(
JSON.stringify({ error: "Search operation failed" }),
{ status: 500, headers: { "Content-Type": "application/json" } }
);
}
// Fetch full component details for results
const enhancedResults = await Promise.all(
searchResults.map(async (result): Promise => {
// Fetch component code
const componentCode = await fetchFileTextContent(result.metadata.code_url as string);
// Fetch demo data if available
const demos = await fetchComponentDemos(result.id);
// Resolve dependencies
const dependencies = await resolveRegistryDependencyTree(result.id);
// Get usage statistics
const { data: usageStats } = await supabase
.from("component_usage_stats")
.select("total_usages")
.eq("component_id", result.id)
.single();
return {
id: result.id,
name: result.name,
code: componentCode,
demos,
similarity_score: result.similarity,
dependencies,
usage_description: result.usage_description || "",
total_usages: usageStats?.total_usages || 0,
};
})
);
// Track component usage for analytics
await supabase.rpc("record_mcp_component_usage", {
component_ids: enhancedResults.map(r => r.id),
search_query: query,
});
return new Response(
JSON.stringify({
results: enhancedResults,
query,
timestamp: new Date().toISOString()
}),
{ status: 200, headers: { "Content-Type": "application/json" } }
);
} catch (error) {
console.error("Unexpected error in search API:", error);
return new Response(
JSON.stringify({ error: "An unexpected error occurred" }),
{ status: 500, headers: { "Content-Type": "application/json" } }
);
}
}
This API handles validation, search execution, result enhancement, and usage tracking — providing a complete pipeline from user query to formatted results.
Challenges and Learnings
Building this system came with several challenges:
1. Code vs. ASTs
While our initial concept involved using Abstract Syntax Trees (ASTs), we found that combining raw code with AI-generated descriptions provided better results with less complexity. ASTs might offer deeper structural insights in the future, but they introduce complexity and potential brittleness.
2. Prompt Engineering
The quality of AI-generated descriptions is critical to search effectiveness. We went through multiple iterations of our prompts:
// Early version of our usage prompt
const EARLY_USAGE_PROMPT = `
Describe what this component does and how it might be used.
`;
// Current version with more structure
const USAGE_PROMPT = `
You are an expert UI developer tasked with describing a React component's functionality.
Analyze the component code and generate a detailed description focusing on:
1. The component's primary purpose and functionality
2. UI appearance and behavior
3. Interactive elements and states
4. Props and customization options
5. Common use cases
Your description should help other developers understand when and how to use this component.
`;
The more structured prompt produces much richer descriptions that capture the component’s purpose, not just its implementation.
3. Embedding Strategy
Our dual embedding approach (usage and code) emerged from experimentation:
- Usage embeddings excel at capturing semantic intent and use cases
- Code embeddings can capture structural patterns that might be missed in descriptions
Together, they provide more comprehensive coverage of both “what it does” and “how it’s built.”
Future Directions
Looking ahead, we’re exploring several enhancements:
1. AST-based Embeddings
While our current approach uses raw code strings, we’re researching ways to incorporate AST-level understanding without sacrificing simplicity.
2. Fine-tuned Embedding Models
We’re experimenting with fine-tuning embedding models specifically for UI component understanding, which could dramatically improve search precision.
Technical Benchmarks and Results
We’ve seen significant improvements in search quality after implementing this system:
- Precision@3: Increased from 0.62 to 0.89 (44% improvement)
- Mean Reciprocal Rank: Improved from 0.58 to 0.83 (43% improvement)
- Time-to-discovery: Reduced by 37% in user testing sessions
The HyDE technique was particularly effective, improving relevance scores by 31% compared to direct query embedding, especially for ambiguous or terse queries.
Conclusion
Our vector embedding approach to UI component search has transformed how developers discover and use components in the 21st.dev ecosystem. By combining AI-generated descriptions, vector embeddings, and advanced retrieval techniques, we’ve created a search experience that understands developer intent, not just keywords.
This system is core to our vision of becoming “the NPM for Design Engineers” — a marketplace where developers can quickly find exactly the UI building blocks they need, regardless of terminology or implementation details.
The techniques described in this article aren’t limited to UI components — they could be applied to any domain where understanding semantic meaning beyond text matching is important, from API endpoints to design patterns
Source code is available on GitHub