The Importance of Disentanglement: SAGE Outperforms Unified VQ-VAE Baselines in Full-Body Motion
Table of Links
Abstract and 1. Introduction
-
Related Work
2.1. Motion Reconstruction from Sparse Input
2.2. Human Motion Generation
-
SAGE: Stratified Avatar Generation and 3.1. Problem Statement and Notation
3.2. Disentangled Motion Representation
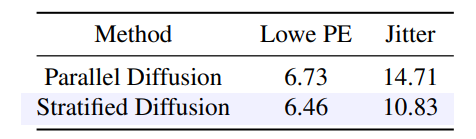
3.3. Stratified Motion Diffusion
3.4. Implementation Details
-
Experiments and Evaluation Metrics
4.1. Dataset and Evaluation Metrics
4.2. Quantitative and Qualitative Results
4.3. Ablation Study
-
Conclusion and References
\
Supplementary Material
A. Extra Ablation Studies
B. Implementation Details
4.3. Ablation Study
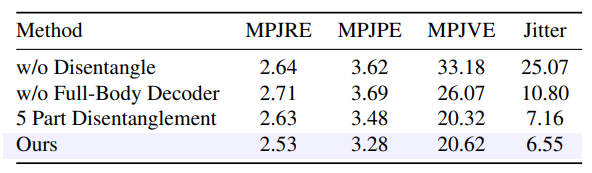
We perform ablation study under S1 to justify the design choice of each component in our SAGE Net.
\
\
\
\
Disentangled Codebook: We establish a baseline using a unified motion representation to evaluate the disentangle strategy. Specifically, we developed a full-body VQ-VAE model that encodes full-body motion into a single, unified discrete codebook. Other components are the same as the original model. Results shown in the first and the last rows in Table 5, demonstrate that our approach employing disentangled latents significantly outperforms the baseline on all evaluation metrics. This demonstrates that the disentanglement can simplify the learning process by allowing the model to focus on a more limited set of movements and interactions. Additionally, Fig. 5 shows the visualization comparison between our model and baseline model, verifying that the disentangle can significantly improve the reconstruction results for the most challenging lower motions.
\

\
Disentanglement Strategy: To investigate the optimal disentanglement strategy, we explore an extreme disentanglement configuration by following the path from the root
\
\
(Pelvis) node to each leaf node along the kinematic tree. Specifically, we break down the body into five segments: the paths from the root to the left hand (a), right hand (b), head (c), left foot (d), and right foot (e). As reported in the last two rows of Tab. 5, the natural joint interconnections within the upper (or lower) body were disrupted when further disentangling the human body, resulting in performance drops and complicating the model design.
\

\
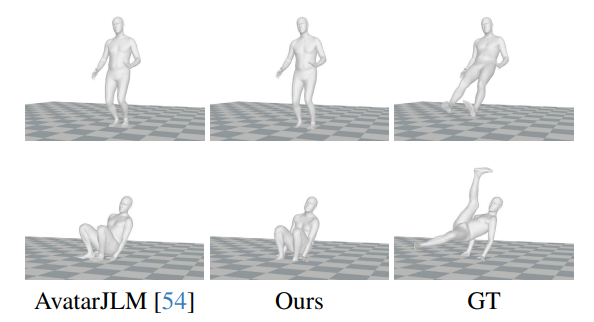
Limitation: In Fig. 6, both the previous state-of-the-art method and our model encounter difficulties in two main situations: (1) External Force-Induced Movements (the top row). (2) Unconventional Poses (the bottom row). The addition of more varied samples to the training dataset can potentially enhance the model’s performance in these areas.
\
:::info
Authors:
(1) Han Feng, equal contributions, ordered by alphabet from Wuhan University;
(2) Wenchao Ma, equal contributions, ordered by alphabet from Pennsylvania State University;
(3) Quankai Gao, University of Southern California;
(4) Xianwei Zheng, Wuhan University;
(5) Nan Xue, Ant Group (xuenan@ieee.org);
(6) Huijuan Xu, Pennsylvania State University.
:::
:::info
This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\